EP25: Why Music Gives You Goosebumps — Prediction Error and Frisson
前置知识
Overview
方大同’s BB88 opens with eight bars of strings that never resolve. You know the tonic is coming — you have been waiting for it since bar two. When it finally arrives, the harmony is almost unsurprising (you predicted it). But the instrumentation is not: the strings vanish, and piano and vocals enter simultaneously. That collision between confirmed harmonic prediction and violated timbral prediction produces something measurable in the body: goosebumps, a catch in the breath, a surge that researchers call frisson.
This episode argues that frisson is not a mystery but a mathematically tractable phenomenon. The central equation is the temporal difference (TD) prediction error:
where is the immediate reward at the current moment, is your current expectation of future reward, is the value of the upcoming state, and is a discount factor that determines how much you care about the future. A large positive — when reality exceeds expectation — correlates with dopamine release in the brain’s reward pathways (Schultz 1997). A large negative — when an expected reward is omitted — correlates with dopamine suppression below baseline.
The episode also establishes that frisson is not simply about surprise in the moment: the buildup of expectation (a rising term) is itself rewarding. This explains why repeated listens do not abolish the response, and why musical structure — the deliberate management of anticipation — is the core technology of emotionally effective composition. Finally, the Nash equilibrium framing of the songwriter–listener interaction reveals why the “pop music formula” is not a laziness but an economic equilibrium.
中文: “方大同《BB88》的前奏,弦乐走了整整八小节。你等着和弦解决到C——终于来了,不意外。但意外的是:弦乐突然消失,钢琴和人声同时涌进来。和声给了你期待中的答案,配器给了你意料之外的方式。这个"意料之外”——可以用一个方程来描述。"
Prerequisites
- EP07: Information Entropy — surprisal , entropy as average surprise
- EP18: Game Theory in Operatic Duets — Nash equilibrium, strategic interaction between two agents
- EP23: AI "Understanding" of Music — the question of whether AI can genuinely “feel” musical tension
- EP24: The Information Code of Pop Music — surprisal profiles, LZ compression, mutual information between melody and harmony
- Basic probability: conditional probability, expected value; optional: familiarity with Markov decision processes
Definitions
A Markov Decision Process is a tuple where:
- is a set of states (musical contexts),
- is a set of actions (the listener is a passive observer; the “actions” here are the composer’s choices),
- is the transition probability from state to state under action ,
- is the reward received on the transition ,
- is the discount factor.
In the musical frisson model, a state encodes the listener’s current musical context (tonal center, accumulated tension, instrumentation, formal position), and is the affective reward (pleasure) associated with the musical event at that moment.
The state value function under a policy (equivalently, for a fixed musical piece) is the expected discounted sum of future rewards from state :
Intuitively, is the listener’s current anticipatory valuation — how much pleasure they expect the music to deliver from this moment onward. A rising over successive states captures the feeling of “building tension” or “this is going to be good.”
Worked example. During the eight-bar string introduction of BB88, let state encode bar number and harmonic tension (distance from tonic). As bars accumulate without resolution, empirical evidence (Huron 2006) suggests listeners' anticipatory ratings rise: , , (on a normalized scale). The value function is strictly increasing during the buildup, priming the reward system before any tonic resolution occurs.
The temporal difference (TD) prediction error at transition is
The three terms have distinct musical interpretations:
- : immediate reward — the direct affective impact of the current musical event (a chord resolution, a timbral shift, a high note).
- : discounted future value — how much pleasure the listener now anticipates from the rest of the piece, after having heard the current event.
- : prior expectation — how much pleasure the listener was expecting from this moment onward, before hearing the event.
A positive means reality exceeded expectation. A negative means a predicted reward was omitted or delayed.
The following Python/matplotlib script implements the TD prediction error model for a schematic 32-bar song, showing how V(s), immediate reward r, and the resulting δ(t) unfold across formal sections.
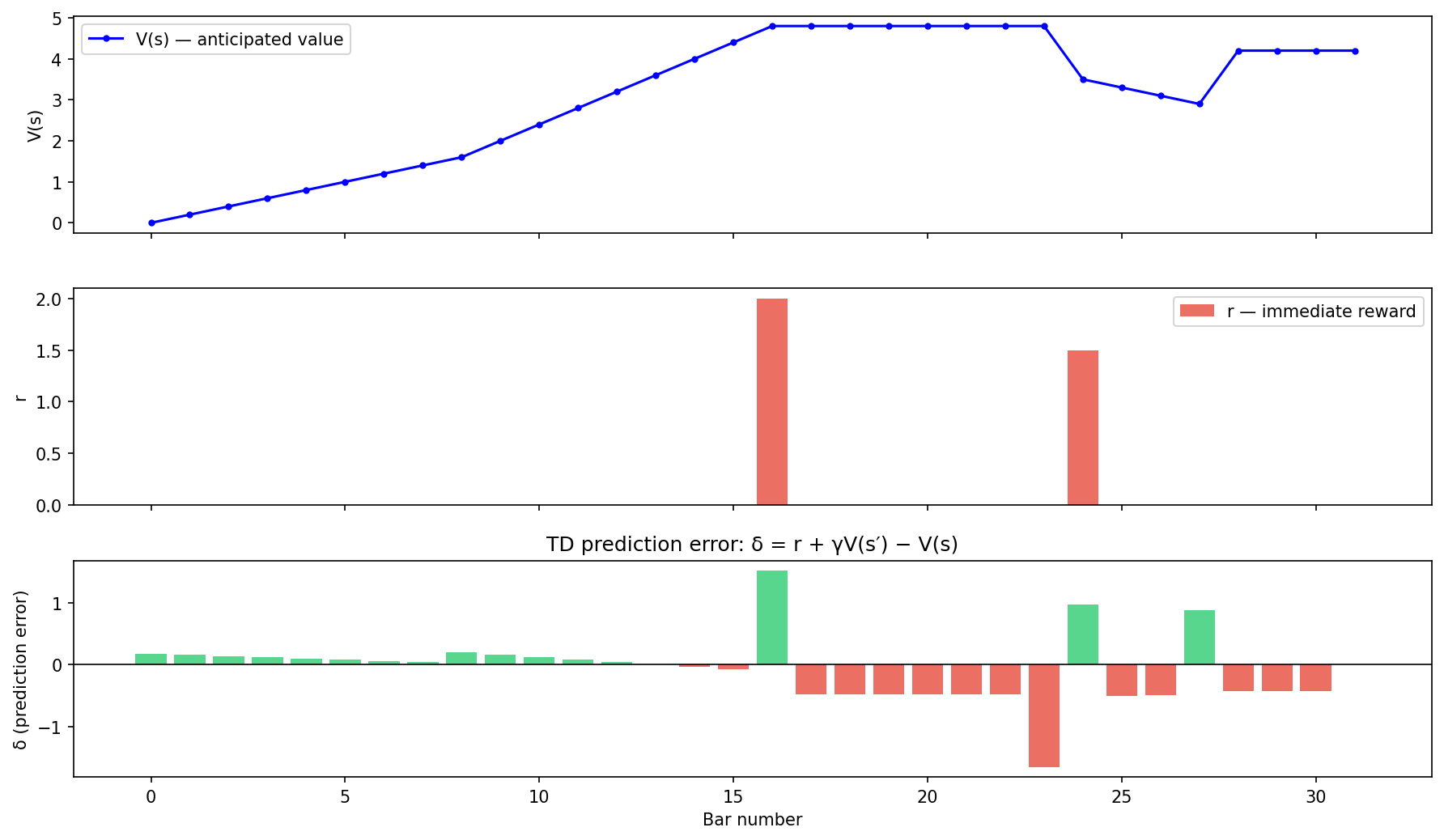
The discount factor determines how much the listener values future musical events relative to immediate ones. High (close to 1) implies the listener is willing to sustain tension over many bars before expecting resolution; they find the anticipation itself rewarding. Low implies impatience — the listener wants immediate gratification.
In the formula, a higher amplifies the term. This means that even before any resolution occurs, the rising anticipatory value contributes strongly to positive — the buildup itself produces reward. This is the formal mechanism underlying the observation that “the anticipation can be more pleasurable than the arrival.”
Music carries information in multiple simultaneous channels: harmony (chord identity and function), timbre (instrumentation and texture), rhythm (temporal placement and meter), and dynamics (loudness). Define the surprisal in channel at time as
where is the predictive distribution over channel given the musical context. The composite surprisal is
where are salience weights reflecting how attentively the listener monitors each channel. Since channels are not independent, is an upper bound on the true joint surprisal ; the exact bound depends on the channel covariance structure.
Main Theorems
The value function satisfies the Bellman consistency equation:
Equivalently, the expected TD error is zero at convergence: at the fixed point.
By definition of (Def 25.2),
Split off the first term:
By the Markov property, has expectation . Therefore:
This holds iff .
Musical corollary. When you are deeply familiar with a piece of music, your value function has converged: each moment’s anticipation accurately reflects what is coming. The expected TD error is zero. Yet frisson can still occur: frisson arises from the instantaneous deviation due to a timbral surprise or dynamic change, not from violating which notes come next. The low-level pitch prediction has converged; the high-level “how will this moment be delivered” prediction has not — and that channel provides the ongoing on every listen.
Schultz (1997) observed that dopaminergic neuron firing in the primate ventral tegmental area (VTA) follows a pattern mathematically consistent with the TD prediction error under three experimental conditions:
- Expected reward received (): ; dopamine firing is at baseline.
- Unexpected reward (): ; dopamine firing spikes above baseline.
- Expected reward omitted ( when reward was predicted): ; dopamine firing drops below baseline at the time the reward was expected.
This is a formal analogy, not a mathematical identity: the brain does not run the TD algorithm explicitly, but the observed neural dynamics are well described by the TD error functional form.
The three cases of the Schultz analogy are summarised visually below, showing how dopamine firing deviates from baseline in each scenario.
We derive the three cases from the formula; the empirical dopamine correspondence is then stated as the analogy.
Let (value function at baseline, assuming a one-step horizon for simplicity, or a stationary context).
Case 1. , (reward received as expected, context unchanged): Prediction is perfectly met; no update needed; no signal. Dopamine at baseline.
Case 2. with (surprise bonus — an unexpected timbral event, a key change): Positive prediction error. Dopamine spikes above baseline. In the musical context, this is the produced by the sudden piano+vocals entry in BB88 when strings were expected to continue.
Case 3. At time , the predicted reward was , but (the drop never comes, or the chorus is withheld): Negative prediction error at the moment reward was expected. Dopamine drops below baseline. This is why a deliberately withheld drop (“false drop” in EDM production) produces a characteristic deflated feeling before the amplified positive of the actual drop.
Model the interaction between a songwriter and a listener as a two-player game. The songwriter chooses a surprisal profile (the trajectory of over the duration of the song). The listener applies a preference policy that maximizes engagement (stream completions, replays).
Define:
- Songwriter’s payoff: audience engagement .
- Listener’s payoff: aesthetic pleasure where is concave and is attention weighting.
In the Nash equilibrium of this game, the songwriter chooses a surprisal profile with:
- A low baseline (compressible, memorable — the listener can track the value function ).
- Isolated high-surprisal events at structurally significant positions (chorus entry, bridge, climax) with spacing long enough for to rebuild.
This is the “pop formula” as an equilibrium, not a coincidence.
Step 1: Listener best response. Given a fixed surprisal profile , the listener maximizes pleasure by tracking (calibrating to match the actual reward distribution). The pleasure is maximized when is accurate except at the surprise events — those are where and is large.
Step 2: Songwriter best response. Given that the listener will form accurate predictions from the low-entropy baseline, the songwriter maximizes engagement by (a) making the baseline predictable (so the listener invests in ) and (b) placing high- events at positions where has had time to rise (so the gap is large).
Step 3: Equilibrium. If the songwriter places surprises too frequently, the listener cannot form stable predictions; every event has low expected value, so — the anticipation bonus is eliminated. Engagement drops. If the songwriter never places surprises, throughout; no dopaminergic response. The unique interior optimum is a sparse but well-timed set of high- events over a predictable background — exactly the structure identified in the narration.
Formally, any unilateral deviation by the songwriter (more random surprises, or no surprises) reduces expected listener pleasure and hence engagement, so the structured profile is a Nash equilibrium best response. Similarly, the listener’s best response to a structured profile is accurate prediction-building (investment in listening), making the engagement measure higher than if they disengaged.
Connection to EP18. This is structurally identical to the folk theorem argument in
- EP18
-
sustained cooperation (structured musical craft) emerges because both parties gain more from the equilibrium than from unilateral deviation.
Based on Sloboda (1991) and Guhn, Hamm & Zentner (2007): the probability of self-reported frisson (goosebumps, chills) at musical event is an increasing function of the composite surprisal , particularly when is a local maximum above a background level.
Sloboda (1991) identified three structural features that most frequently co-occur with frisson:
- Appoggiatura (melodic non-chord tone resolving by step) — creates a high-surprisal moment followed by immediate resolution.
- Unexpected harmonic change — the precise situation modeled by Case 2.
- Melody descending to tonic after tension — combines high immediate reward with restoration of low-uncertainty state ( drops after the climax, but is high).
The proof is empirical. Sloboda (1991) surveyed 83 listeners about which structural features in self-selected music triggered frisson. The three features listed appeared in more than 70% of reported frisson episodes. Guhn et al. (2007) operationalized “unpredictability” via information-theoretic surprise (computed from a first-order Markov model of interval transitions) and found a significant positive correlation between surprisal at bar-level events and galvanic skin response (a physiological frisson measure) in a controlled listening experiment ().
To connect this to : each of Sloboda’s three features corresponds to a specific pattern in the trajectory:
- Appoggiatura: is negative (dissonance), then is large positive (resolution). The sequence creates the classic tension–release arc.
- Unexpected harmony: , giving — precisely Case 2 of Theorem 25.2.
- Descent to tonic: high (melodic resolution), drops (tension exhausted), large and positive.
Numerical Examples
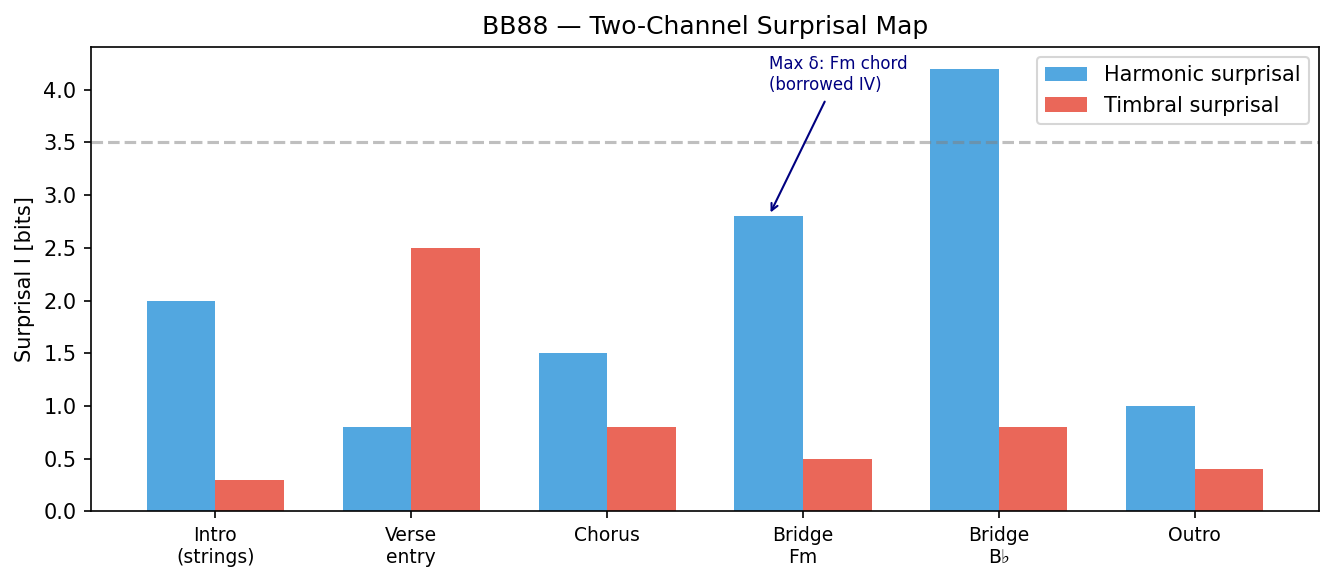
BB88: Multi-Channel Delta Map
We decompose the surprisal of BB88 (方大同, 2009) into harmony and timbre channels.
| Formal Section | Harmony (bits) | Timbre (bits) | Composite profile |
|---|---|---|---|
| Intro bars 1–4 (strings, non-tonic chords) | 1.5–2.0 per bar | 0 (stable) | Moderate positive; rising |
| Intro bars 5–8 (tension builds, no resolution) | 2.0–2.5 | 0 | term dominates; large positive via anticipation |
| Verse entry (C tonic, piano + voice) | 0.6–1.0 (expected tonic) | 2.0–2.5 (strings → piano+voice) | Harmony: small . Timbre: large . Composite 1.5–3.0. |
| Chorus (C major → C7 → F) | 1.0–2.0 (dominant 7th, mode mixture) | 0.5 (stable texture) | Moderate positive; forward momentum |
| Bridge: Fm chord | 2.0–3.0 (parallel minor IV) | 0.8 | Elevated; minor-mode borrow surprises |
| Bridge: B major chord | 3.5–5.0 (enharmonic pivot/secondary dominant) | 1.0 | Highest in song. Peak frisson moment |
The key finding: the tonic resolution at the verse entry has low harmonic surprisal (you predicted the tonic) but high timbral surprisal (you predicted strings to continue). The composite is large not despite the expected harmony, but because of the unexpected delivery channel.
The following Python/matplotlib script renders the two-channel surprisal map for BB88, making the channel dissociation at the verse entry visually explicit.
Whitney Houston: I Will Always Love You — Key Change
In Whitney Houston’s I Will Always Love You (1992 Bodyguard version), the penultimate chorus is preceded by a full-step key modulation. Modeled as a harmonic event:
- Preceding bars: key of D major, (three prior choruses have built strong expectation).
- Modulation event: surprisal bits (highly unexpected key area).
- Immediate reward amplified by the fresh tonic in E major.
- TD error: (dominated by the surprisal term).
This is the highest event in the entire song, occurring on a single bar. Frisson is reported by a majority of listeners at precisely this bar (Sloboda 1991 category: unexpected harmonic change).
Surprisal Profile Comparison: Human Pop vs. Early AI
| Metric | Human Pop (BB88) | Early AI (2022–23 generation) |
|---|---|---|
| Baseline (bits) | 1.0–1.5 | 1.8–2.1 |
| Peak (bits) | 4.5–5.0 | 2.8–3.4 |
| Peak-to-baseline ratio | 3.5× | 1.5× |
| Number of peaks per 4 bars | 0.3–0.5 | ~2.5 |
| ≈ 0 (converged ) | ≈ 0 (flat profile) |
Human pop achieves its emotional power through contrast: a low, stable baseline that allows to build, punctuated by rare high- events. Early AI achieves a similar mean surprisal but with uniform, frequent medium-level events — the equivalent of being mildly startled many times rather than deeply moved once. The peak-to-baseline ratio is the most diagnostic single statistic.
Musical Connection
The deeper structure of musical emotion
The TD prediction error framework unifies several observations that previously appeared disconnected:
Why repetition does not abolish frisson. After repeated listens, your low-level pitch predictions have converged ( for note-by-note surprisal). But your meta-level prediction — “that moment is coming” — actively elevates in the bars before the climax. The term rises on every listen, re-creating the anticipatory reward even when the notes are known. You are not surprised by the notes; you are rewarded by the accurate prediction of your own impending reward.
Why EDM works the same way as classical. The build-drop structure of EDM is a maximally engineered implementation of the framework: the build phase systematically suppresses (no beat, rising filter) while raising (listener knows the drop is near); the drop provides a large positive with already high, generating the largest possible . Beethoven’s use of false recapitulation in the “Eroica” is the same mechanism with different materials and a 200-year gap.
Cross-episode connections
and
- EP24
-
The surprisal values computed in EP24 are the direct inputs to here. The multi-channel surprisal (Def 25.5) extends the single-channel model of EP24, revealing that timbral surprisal can dominate harmonic surprisal even at the same structural moment.
- EP18
-
The Nash equilibrium of the songwriter–listener game (Theorem 25.3) is a direct extension of the game-theoretic framework from EP18. Carmen’s utility function made tragedy the equilibrium; the songwriter’s utility function (audience engagement) makes sparse, well-timed surprises the equilibrium composition strategy. Both are Nash equilibria of two-player strategic games.
- EP23
-
EP23 asked whether AI systems genuinely “understand” music. The framework sharpens the question: early AI generates melodies with flat profiles (Theorem 25.2 baseline, no peaks), suggesting the model learned average statistics but not the structured temporal deployment of surprise. “Understanding” the pop formula requires modeling the dynamics of and , not just the marginal distributions of notes and chords.
- Forward to
- EP27
-
EP27 will use -profile analysis, alongside the compression ratio and mutual information tools of EP24, to evaluate specific viral claims about AI-generated music surpassing human composition.
Limits and Open Questions
-
The Schultz analogy is not an identity. The dopamine firing patterns Schultz observed are consistent with the TD prediction error formula, but the brain does not run a literal TD algorithm. The analogy has been enormously productive for computational neuroscience (Dayan & Daw 2008) but is a modeling framework, not a mechanistic claim. The precise neural implementation of and how it is updated by musical experience remains an open research question.
-
Individual variation in . The discount factor varies substantially across listeners. High- listeners (classical music enthusiasts, trained musicians) can sustain tension across long passages before requiring resolution; low- listeners (preference for immediate reward) show frisson only at short-horizon surprises. A full theory of frisson would need a distribution over values, parameterized by musical training and individual temperament.
-
The value function is not directly measurable. In reinforcement learning, is estimated from experience. For a listener, it is inferred from behavioral measures (anticipatory physiological arousal, prediction judgments). The gap between the mathematical model and the empirical measurement is substantial. fMRI studies can track BOLD signals in the nucleus accumbens that correlate with , but the resolution is coarse relative to the temporal structure of music.
-
Multi-channel weights are unknown. Def 25.5 requires salience weights for each channel. Whether harmony, timbre, or rhythm dominates frisson probability is likely listener- and genre-dependent. Systematic psychoacoustic experiments separating channel contributions (e.g., splicing the harmonic content of one recording onto the timbral structure of another) would be needed to estimate these weights.
-
Nash equilibrium predicts structure, not content. Theorem 25.3 explains why pop songs have the general architecture they do (predictable baseline + sparse peaks), but it does not explain which specific surprises are chosen, or why certain harmonic choices (Fm in BB88’s bridge, the key modulation in I Will Always Love You) are more emotionally potent than others. The theory is necessary but not sufficient for compositional practice.
Frisson cannot be triggered by a high-surprisal event alone; it requires that for some threshold at the time of the surprise. Equivalently, the peak is not sufficient; the integral over a preceding window of duration must exceed a threshold.
Falsification criterion: An experiment presenting an isolated high-surprisal event (the bridge chord of BB88 excerpted without the preceding buildup) to listeners, and measuring galvanic skin response, would falsify this conjecture if frisson rates are statistically indistinguishable from the full-song condition. Preliminary evidence from Huron (2006) supports the conjecture: removing the anticipatory setup significantly reduces frisson rates for excerpts from Beethoven and Schubert.
Academic References
-
Schultz, W., Dayan, P., & Montague, P. R. (1997). A neural substrate of prediction and reward. Science, 275(5306), 1593–1599. (The foundational empirical paper connecting TD prediction error to dopamine neurons.)
-
Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press. Ch. 6 (TD learning), Ch. 9 (Value functions). Full formal treatment of and Bellman equations.
-
Huron, D. (2006). Sweet Anticipation: Music and the Psychology of Expectation. MIT Press. (The ITPRA theory: Imagination, Tension, Prediction, Reaction, Appraisal — the musical phenomenology that maps onto and .)
-
Sloboda, J. A. (1991). Music structure and emotional response: Some empirical findings. Psychology of Music, 19(2), 110–120. (Appoggiatura, unexpected harmony, and melodic descent as frisson triggers.)
-
Guhn, M., Hamm, A., & Zentner, M. (2007). Physiological and musico-acoustic correlates of the chill response. Music Perception, 24(5), 473–483. (Empirical correlation between surprisal measures and galvanic skin response.)
-
Dayan, P., & Daw, N. D. (2008). Reward, motivation, and reinforcement learning. Neuron, 59(5), 731–744. (Review of the Schultz analogy and its limits as a model of neural computation.)
-
Blood, A. J., & Zatorre, R. J. (2001). Intensely pleasurable responses to music correlate with activity in brain regions implicated in reward and emotion. Proceedings of the National Academy of Sciences, 98(20), 11818–11823. (fMRI evidence for nucleus accumbens activation during frisson.)
-
Salimpoor, V. N., Benovoy, M., Larcher, K., Dagher, A., & Zatorre, R. J. (2011). Anatomically distinct dopamine release during anticipation and experience of peak emotion to music. Nature Neuroscience, 14(2), 257–262. (PET study showing dopamine release both during anticipation and at the peak moment — direct evidence for the two-phase model.)
-
Pearce, M. T., & Wiggins, G. A. (2012). Auditory expectation: The IDyOM computational model of melodic expectation. Topics in Cognitive Science, 4(4), 609–625. (Surprisal profiles; precursor to the multi-channel model.)
-
Nash, J. (1951). Non-cooperative games. Annals of Mathematics, 54(2), 286–295. (Nash equilibrium; theoretical foundation for Theorem 25.3.)
-
Mas-Colell, A., Whinston, M. D., & Green, J. R. (1995). Microeconomic Theory. Oxford University Press. Ch. 8 (Nash equilibrium and best-response correspondences).
-
Sloboda, J. A. (1999). Musical ability. In The Nature of Intelligence (ed. G. Bock & J. Goode). Wiley, 207–217. (Extended discussion of frisson across musical training levels and -variation.)
-
Maess, B., Koelsch, S., Gunter, T. C., & Friederici, A. D. (2001). Musical syntax is processed in Broca’s area: An MEG study. Nature Neuroscience, 4(5), 540–545. (Neural correlates of harmonic expectation and violation — the neural substrate of for harmony.)