EP30: The Sampling Theorem Is Not What You Think
后续拓展
Overview
“Digital audio is a staircase waveform — the signal between sample points is guessed, so digital is less natural than analog.” This claim is widespread, yet it fundamentally misunderstands the mathematics of signal reconstruction. The Nyquist-Shannon sampling theorem tells us: if a signal is bandlimited, its original continuous waveform can be perfectly reconstructed from uniformly spaced discrete samples alone — not approximately, but exactly. The key to reconstruction is the sinc function, which fills in between discrete samples not with guesses, but with values uniquely determined by those samples.
Yet sampling is only the first stage of the digital audio pipeline. The central argument of this episode is: sampling is not the most fragile link in digital audio — quantization is. Quantization maps continuous amplitude to a finite number of levels, inevitably introducing truncation error. Without mitigation, the quantization error of a low-level signal is highly correlated with the signal itself, producing harsh harmonic distortion rather than an acceptable white noise floor. The technical chain that solves this problem — dithering and noise shaping — is the real reason the CD format at 44.1 kHz / 16-bit still sounds so good.
This episode derives the sampling theorem in the frequency domain, proceeds through the quantization SNR formula derivation, then to the proof of the TPDF triangular probability distribution, and finally analyzes the first-order noise shaping transfer function , providing a complete mathematical picture of the digital audio conversion chain.
中文: “你有没有听过这种说法:数字音频是阶梯波,每个采样点之间的信号是’猜’出来的,所以数字不如模拟’自然'。这是错的。采样定理告诉我们,只要采样率足够高,原始信号可以被完美重建——不是近似,是完美。重建的工具,叫sinc函数。今天我们把这件事从头算清楚。”
Prerequisites
- Wave equation and Fourier series (EP02) — frequency-domain analysis, convolution theorem, power spectral density
- Shannon information theory (EP07) — information entropy, bit rate, Shannon capacity theorem (and the information-theoretic context of the Nyquist theorem)
Definitions
A real-valued signal is said to be bandlimited to Hz if its Fourier transform
satisfies for all . That is, all energy of the signal is concentrated in the frequency interval .
Example: The upper limit of human hearing is approximately 20 kHz, so for speech/music signals Hz is sufficient.
The normalized sinc function is defined as
Key properties:
- ;
- for all nonzero integers ;
- ;
- Its Fourier transform is a rectangular window: .
Intuition: The sinc function is an “ideal interpolation impulse” — it equals 1 at its own time instant and equals 0 at all other integer time instants.
Given an -bit quantizer with full-scale signal range , the range is divided uniformly into levels. The quantization step size (least significant bit, LSB) is
The quantization function rounds the input to the nearest level. The quantization error is defined as , satisfying .
Example (16-bit, full scale ±1 V): . A single level is only 30 microvolts wide — this is the precision of CD quantization.
Triangular Probability Density Function (TPDF) noise has probability density
This is a triangular distribution on , with zero mean and variance .
Why triangular? The probability density of the difference of two independent random variables uniformly distributed on is exactly the convolution of two rectangular functions, which yields a triangle (see Theorem 30.3).
In the -domain, the frequency response of a discrete-time filter acting on quantization error is called the Noise Transfer Function (NTF). For a first-order error-feedback noise shaper, the NTF is defined as
Its frequency response (setting ) is
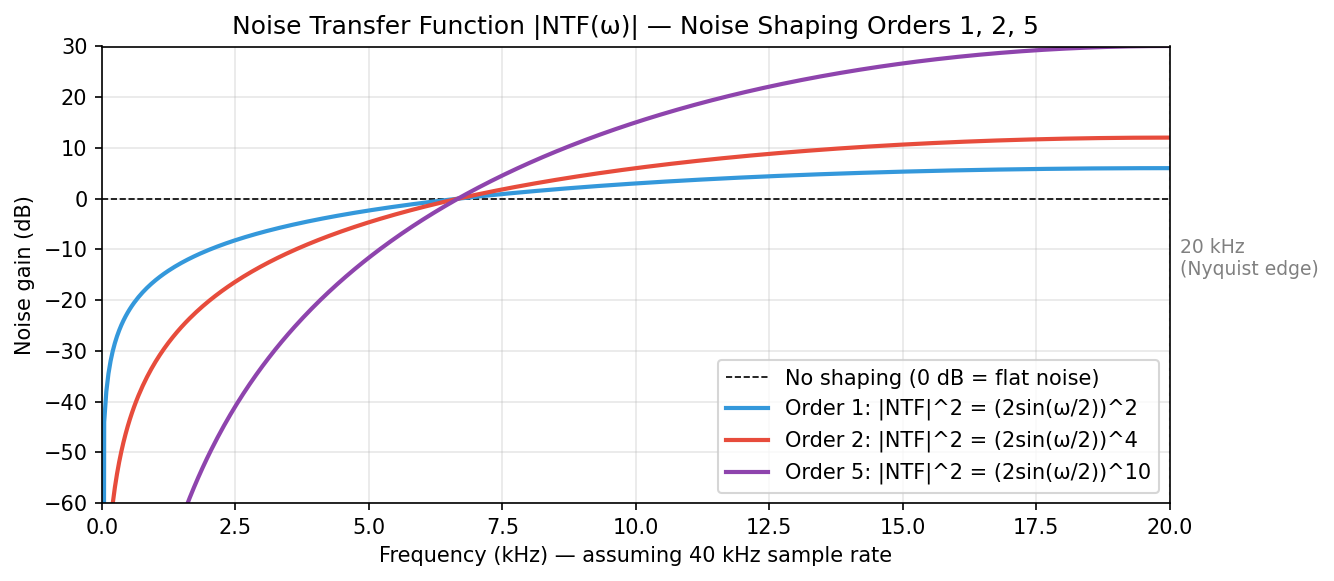
This is zero at (DC) and reaches its maximum value of 4 at (Nyquist). This means noise energy is “pushed” from low frequencies toward high frequencies.
Main Theorems
Let be a signal bandlimited to Hz, i.e., for . Choose sampling interval (equivalently, sampling rate ). Then is completely determined by its sample sequence and is exactly reconstructed by
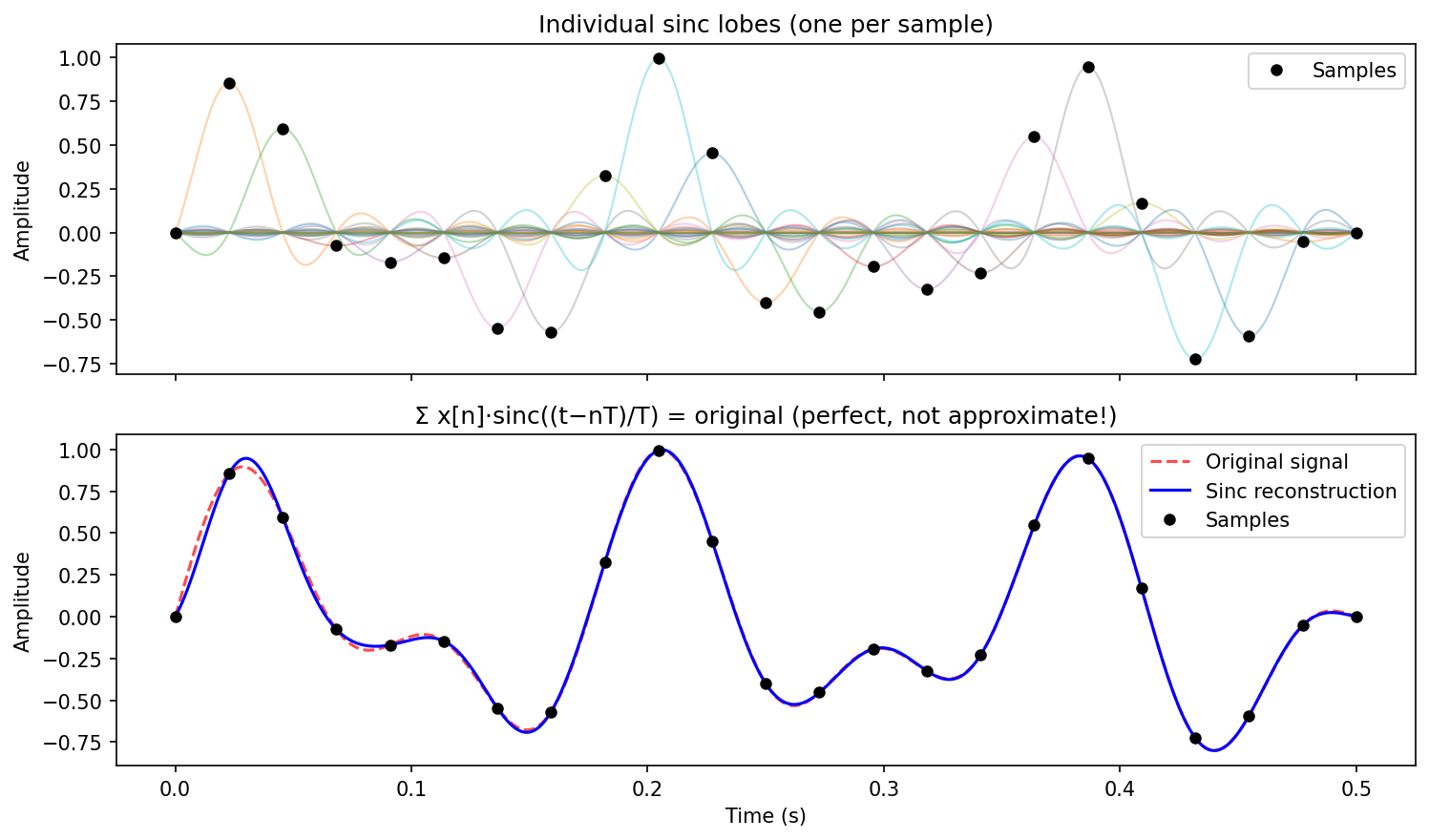
Conclusion: For bandlimited signals, discrete sampling loses no information; the “staircase approximation” is an artifact of zero-order hold circuits, not an inherent consequence of the sampling theorem.
Step 1: Sampling = multiplication by a Dirac comb.
Ideal sampling of is equivalent to multiplying by a Dirac comb with period :
Step 2: In the frequency domain, sampling = periodic replication of the spectrum.
By the convolution theorem, multiplication in time corresponds to convolution in frequency. The Fourier transform of the comb is again a comb:
Therefore
That is, is a periodic superposition of copies of with period .
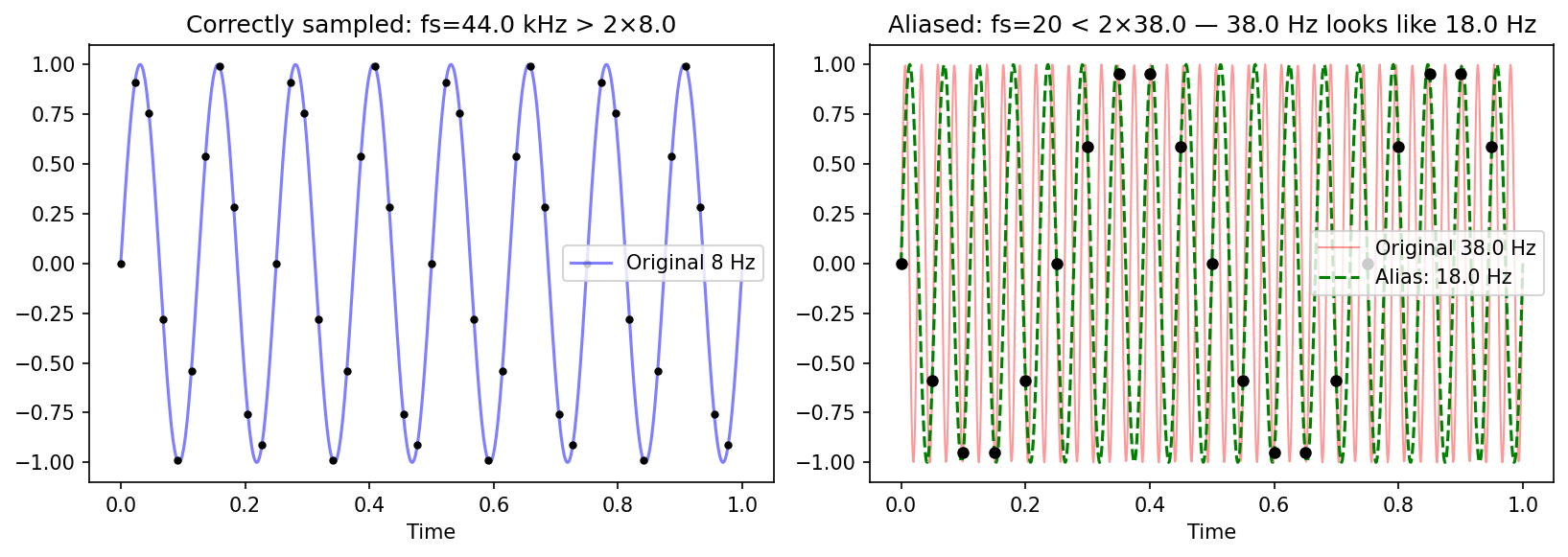
Step 3: No-aliasing condition ⟺ copies do not overlap.
Since is bandlimited to , each copy has support on . Adjacent copies ( and ) do not overlap if and only if
Step 4: Reconstruction = multiplication by a rectangular low-pass filter.
Under the no-aliasing condition, multiplying by the rectangular window exactly recovers . In the time domain this corresponds to convolution with the sinc function:
This is exactly the reconstruction formula in the theorem.
Verification of the interpolation property: At , . Since , this is 0 when and 1 when . So the right-hand side exactly recovers at .
The following script visualizes the sinc interpolation process: each sample point excites a sinc lobe, and all lobes sum to exactly reconstruct the original bandlimited signal.
The following script demonstrates aliasing: when the sample rate is below twice the signal frequency, the high-frequency signal is “folded” into an incorrect lower-frequency component.
For an -bit uniform quantizer, the signal-to-noise ratio for a full-scale sinusoidal signal is
Specifically, each additional bit increases the SNR by approximately 6 dB.
Quantization error power: In the standard model of uniform quantization, the quantization error is modeled as a random variable uniformly distributed on . Its power (variance) is
Full-scale sinusoidal signal power: Let the full-scale sine wave be , where (so the peak exactly reaches the quantization range limit). Its power is
Linear SNR ratio:
Converting to decibels:
That is, dB.
Let , and let . Then:
- Distribution: follows a triangular distribution on with probability density
-
Variance: ;
-
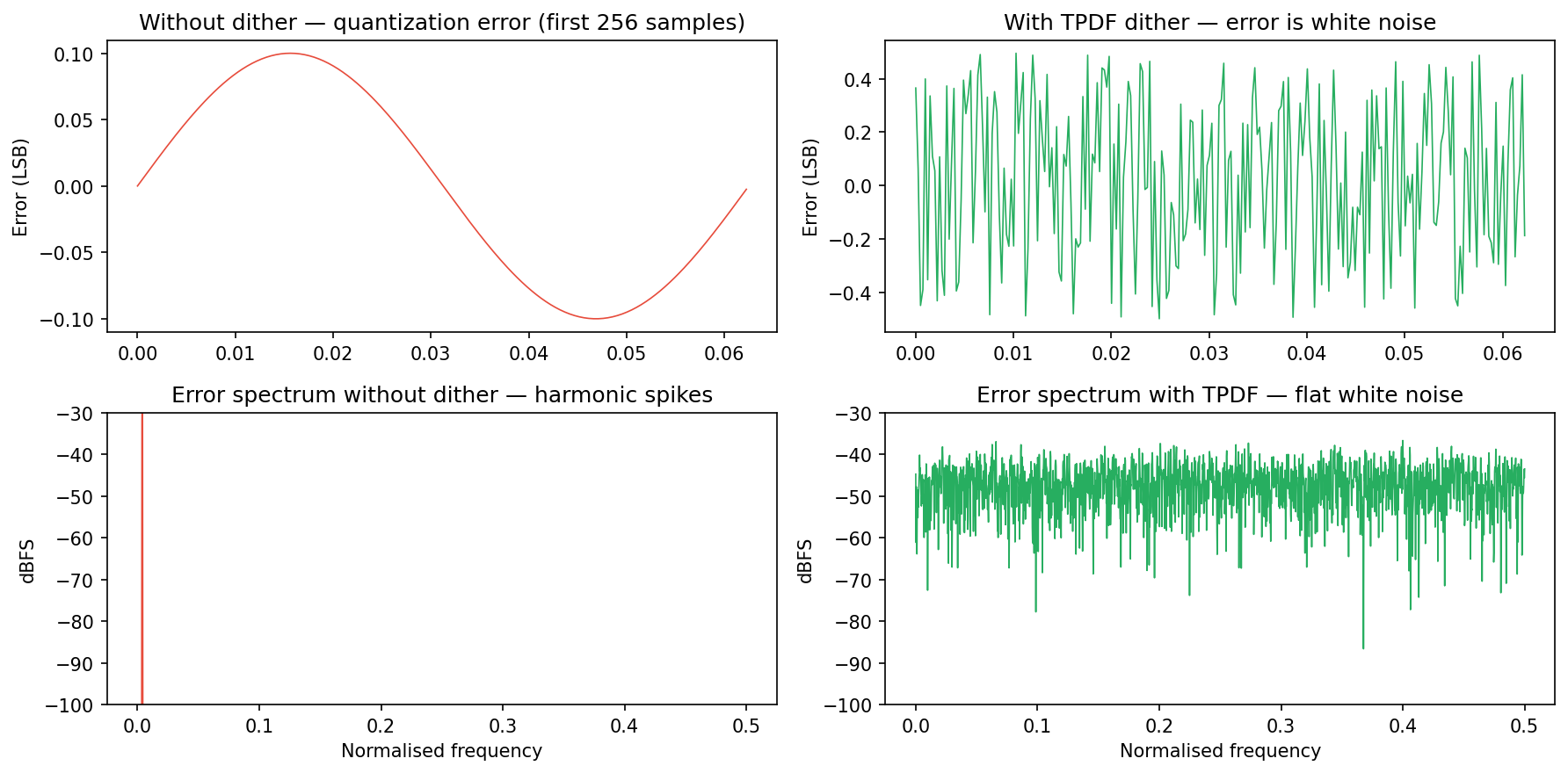
Independence: If TPDF noise is added to the signal before quantization, the statistical properties of the quantization error are independent of the input signal .
Part 1 (triangular distribution):
The probability density of is the convolution of the densities of and . Since (uniform distribution is symmetric about zero),
where . Computing the integral:
For , the integrand is nonzero only when and , i.e., intersected with gives , of length . Therefore
Since the distribution of is symmetric about 0 (because are identically distributed), for we have , which combines to .
Part 2 (variance):
Part 3 (independence):
Adding TPDF noise to the signal before quantization, the value being quantized is . The key observation is that has range , width , while the quantization step size is . For any fixed , the quantity takes values over a range of width according to a triangular distribution; since the integral of the triangular distribution over any -wide interval is completely determined by the distribution of , the distribution of the post-quantization error does not depend on which quantization bin falls in. Therefore is statistically independent of , and the quantization error degrades from harmonic distortion to signal-independent white noise.
The following script compares quantization error with and without TPDF dithering — four panels showing time-domain waveforms and spectra, clearly illustrating how harmonic distortion is eliminated and converted to flat white noise.
Let the noise transfer function of a first-order error-feedback noise shaper be
Then:
- Frequency response: Setting ( is the normalized angular frequency),
- Low-frequency noise suppression: Within bandwidth (), the ratio of in-band noise power after shaping compared to unshaped is approximately
- Zero at DC: ; Maximum at Nyquist: .
Part 1 (frequency response derivation):
Setting ,
Using the identity , taking the squared modulus:
Part 2 (low-frequency noise power):
Without shaping, quantization noise power is uniformly distributed over (white noise). After shaping, the in-band noise power is proportional to
Using (), letting :
Without shaping, the in-band noise power is proportional to (white noise uniformly distributed). The suppression ratio from shaping is therefore
For the CD format (44.1 kHz sampling, 20 kHz audio bandwidth), , and the noise power is substantially redistributed away from the audio band, giving a perceptual in-band SNR gain equivalent to approximately 2 bits.
Part 3:
: . : .
The following script plots the magnitude response of first-, second-, and fifth-order NTFs, illustrating how noise is pushed from the low-frequency region toward the Nyquist edge.
Numerical Examples
SNR at different bit depths (full-scale sinusoidal signal, uniform quantization):
| Bit depth | Theoretical SNR (dB) | Equivalent dynamic range | Notes |
|---|---|---|---|
| 8 | 49.9 | ~50 dB | Early game consoles, telephone voice |
| 16 | 98.1 | ~98 dB | CD format, covers full human hearing dynamic range |
| 24 | 146.2 | ~146 dB | Professional recording, ~60 dB beyond human hearing limit |
| 32 | 194.2 | ~194 dB | Floating-point format, practically limited by noise floor |
Verification (16-bit):
Verification (24-bit):
The human ear’s dynamic range spans from 0 dB (hearing threshold) to 120 dB (pain threshold), a total of 120 dB. 16-bit already provides approximately 98 dB, which exceeds the requirements of real-world audio use cases (a professional recording studio noise floor is around -70 dBFS). The extra 48 dB of 24-bit is not for the listener — it is headroom for engineers during gain adjustments, mix compression, and other processing.
中文: “代入具体数字:十六比特给出约九十八分贝——覆盖人耳动态范围。二十四比特给出约一百四十六分贝——超过人耳极限六十分贝。所以专业录音用二十四比特,不是为了你能听到更多细节,而是给工程师留了足够的增益余量。”
TPDF noise variance calculation:
TPDF noise has variance , which is twice the uniform quantization error variance . This is the cost of dithering: the noise floor power doubles (approximately +3 dB), but in exchange the quantization error becomes statistically independent of the signal.
Noise shaping gain estimate:
Effective noise suppression of the first-order NTF within the audio band (0–20 kHz):
This means approximately 14% of the noise energy remains in the audio band; the rest is pushed above 20 kHz. A fifth-order NTF can further reduce this fraction to give a perceptual SNR gain equivalent to +4 bits.
Musical Connection
Why CDs sound better than theory predicts
Theory tells us that 16-bit gives an SNR of approximately 98 dB; the human ear’s dynamic range is approximately 120 dB; seemingly the CD format has a 22 dB gap. In practice, however, modern CD players add TPDF dithering and noise shaping before D/A conversion, eliminating harmonic distortion components in the quantization error and pushing noise energy above 20 kHz — beyond the range of human hearing sensitivity. The final perceived SNR can be equivalent to 18–20 bit quantization depth, far exceeding the theoretical 16-bit calculation. Behind the engineering conclusion that “the CD format is good enough” lies the precise collaboration of three theorems: the sampling theorem ensures no aliasing, the TPDF theorem eliminates harmonic distortion, and the NTF theorem pushes the cost outside the audible range.
The analog counterpart
Noise shaping was not invented for digital audio. The pre-emphasis/de-emphasis networks in analog AM broadcasting boost high-frequency signals at the transmitter and reverse this at the receiver, achieving an effect analogous to noise shaping: the channel noise (predominantly at high frequencies) is suppressed by the de-emphasis filter after demodulation. This idea corresponds exactly to the error feedback of the NTF — one is implemented in the analog frequency domain, the other in the digital -domain.
Connection to EP02: the sampling theorem from a Fourier perspective
revealed the duality between the time domain and frequency domain. The sampling theorem is a precise exploitation of this duality: discrete sampling in the time domain (a periodic impulse sequence) is equivalent to periodic replication in the frequency domain. The bandlimited condition ensures the copies do not overlap, making reconstruction uniquely determined. “Sampling = amplitude discretization” and “quantization = amplitude discretization” form two orthogonal dimensions of digital audio, each requiring independent mathematical tools for analysis and compensation.
Forward connections to EP35 and EP39
In
, sinc interpolation is used directly in time-stretching algorithms: re-interpolating the phase of frequency bins in the transform domain is mathematically identical in structure to the Whittaker-Shannon reconstruction formula.
In
, True Peak detection also relies on sinc interpolation: the PCM waveform is upsampled by 4× before taking the maximum value, to detect amplitude overshoots that may exist between sample points. This is a direct engineering application of the sampling theorem from this episode — when the sample rate is high enough, inter-sample peaks can be precisely predicted.
Limitations and Open Problems
-
Physical unrealizability of the ideal sinc: The Whittaker-Shannon reconstruction formula requires an infinitely long sinc convolution kernel, which is not implementable in real-time systems. Practical DACs use finite-length FIR filter approximations, introducing truncation error (Gibbs phenomenon) and linear phase delay. The parameter selection of optimal truncation windows (Kaiser window, Blackman-Harris window, etc.) is an ongoing engineering optimization problem.
-
Unified framework of oversampling and Sigma-Delta modulation: Nearly all modern high-resolution audio ADCs use a Sigma-Delta (∑-Δ) architecture: first performing 1-bit quantization at a very high sample rate (several MHz), then downsampling through digital filters. This integrates TPDF dithering, noise shaping, and sample rate conversion into a unified architecture. Its precise noise analysis requires high-order NTFs (e.g., fifth- or seventh-order), beyond the scope of the first-order analysis in this episode.
-
Cooperation between non-uniform quantization and perceptual coding: This episode assumes uniform quantization (equal width per level). In practice, the human ear is far more sensitive to low-level signals than high-level ones. μ-law/A-law companding (telephone voice) and the bit allocation algorithms of MP3 (see EP40) are both based on perceptually weighted non-uniform quantization, achieving higher perceptual quality at the same bit count.
-
Optimal choice of dither spectrum: TPDF is not the only dithering strategy. Gaussian dither has shorter correlation, and blue-noise (high-pass shaped) dither can further push the noise floor energy toward high frequencies. A rigorous proof of optimality for the dither spectrum that minimizes perceived noise floor in a formal sense is currently lacking.
Intuitively, the higher the NTF order, the stronger the in-band noise suppression and the higher the perceptual SNR. However, high-order NTFs exhibit sharply increasing noise gain near Nyquist, which can cause quantizer overload and system instability. Conjecture: For a system with 44.1 kHz sampling and 20 kHz audio bandwidth, there exists an optimal NTF order that maximizes perceptually weighted SNR subject to stability constraints, and .
Falsifiability criterion: If there exists an NTF of order that is stable (no overload on any full-scale sinusoidal input) and exceeds the best known seventh-order design in A-weighted SNR, then this conjecture is falsified.
References
-
Shannon, C. E. (1949). Communication in the presence of noise. Proceedings of the IRE, 37(1), 10–21. (Original proof of the sampling theorem)
-
Nyquist, H. (1928). Certain topics in telegraph transmission theory. Transactions of the AIEE, 47(2), 617–644.
-
Whittaker, E. T. (1915). On the functions which are represented by the expansions of the interpolation theory. Proceedings of the Royal Society of Edinburgh, 35, 181–194.
-
Wannamaker, R. A., Lipshitz, S. P., Vanderkooy, J., & Wright, J. N. (2000). A theory of nonsubtractive dither. IEEE Transactions on Signal Processing, 48(2), 499–516. (Rigorous proof of TPDF independence)
-
Lipshitz, S. P., & Vanderkooy, J. (1992). Dither in digital audio. Journal of the Audio Engineering Society, 40(12), 966–979.
-
Adams, R. W. (1986). Design and implementation of an audio 18-bit analog-to-digital converter using oversampling techniques. Journal of the Audio Engineering Society, 34(3), 153–166. (Pioneering paper on ∑-Δ)
-
Norsworthy, S. R., Schreier, R., & Temes, G. C. (Eds.). (1997). Delta-Sigma Data Converters: Theory, Design, and Simulation. IEEE Press.
-
Zölzer, U. (2008). Digital Audio Signal Processing (2nd ed.). Wiley. Ch. 3 (Quantization).
-
Smith, J. O. (2011). Spectral Audio Signal Processing. CCRMA, Stanford University. (Open textbook, online: ccrma.stanford.edu/~jos/sasp)
-
Pohlmann, K. C. (2010). Principles of Digital Audio (6th ed.). McGraw-Hill. Ch. 2 (Sampling and Quantization).
-
Proakis, J. G., & Manolakis, D. G. (2006). Digital Signal Processing: Principles, Algorithms, and Applications (4th ed.). Pearson. Ch. 4.
-
ITU-R BS.1770-4. (2015). Algorithms to measure audio programme loudness and true-peak audio level. ITU Radiocommunication Sector. (True peak detection, related to EP39)